How DB2 Data sharing groups are implemented
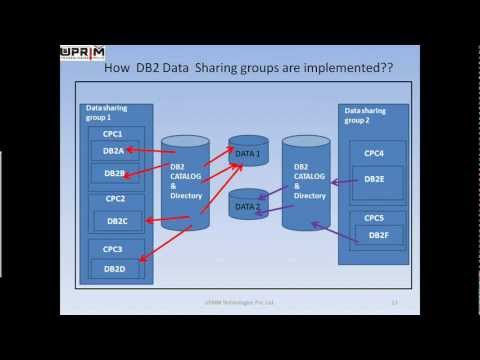
DB2 version 4.1 made it possible for applications running on seperate DB2 subsystems to share data. That meant that these applications could have read and updated the data in the same dataset (file) at the same time.
Today DB2 data sharing is done on one of the most advanced Z-OS configuration, the paralle sysplex. In the early 1990’s, many mainframe shops began looking at the possibility of replacing their mainframes with PC based networks to manage large volumes of data. However, several factors affected them from switching over to new system. The most common factor was the inability of the PC based system to handle large quantity of Data.
Key Learnings of the session will be:
Introduction to SINGLE System Uni-Processor
A tightly coupled multi processor
A loosely coupled multi processor
A Base sysplex
A parallel sysplex
How parallel processing is implemented on Parallel sysplex?
How DB2 data sharing groups are implemented?
How DB2 uses coupling facility to share data?